VAX / VMS 虚拟内存系统
数字设备公司(DEC)在 20 世纪 70 年代末推出了 VAX-11 小型机体系结构。该架构有许多实现,包括 VAX-11/780 和功能较弱的 VAX-11/750。
该系统的操作系统被称为 VAX/VMS(或者简单的 VMS),其主要架构师之一是 Dave Cutler,他后来领导开发了微软 Windows NT。
VMS 将运行在各种机器上,包括非常便宜的 VAXen(是的,这是正确的复数形式),以及同一架构系列中极高端和强大的机器。因此,操作系统必须具有一些机制和策略,保证其适用于这一系列、不同性能的机器(并且运行良好)。
操作系统常常有所谓的“通用性魔咒”问题,它们的任务是为广泛的应用程序和系统提供一般支持。通用意味着中庸或者说平庸,但是至少对于任何类型的负载来说它都能用。
内存管理硬件
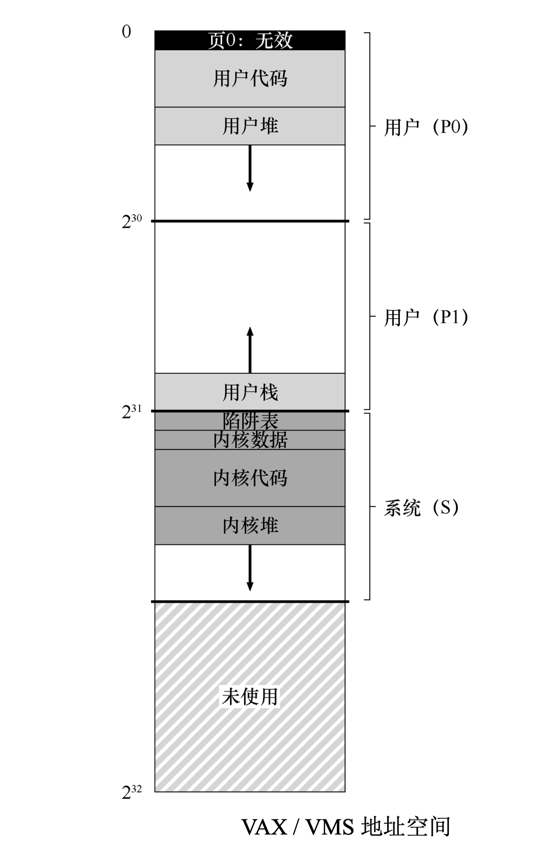
- VAX-11 为每个进程提供了一个 32 位的虚拟地址空间,分为 512 字节的页。
- 因此,虚拟地址由 23 位 VPN 和 9 位偏移组成。
- VPN 的高两位用于区分页所在的段。因此,如前所述,该系统是分页和分段的混合体。
对于物理内存来说
- 将内存一分为二
- 前半段为系统空间
- 受保护的操作系统代码和数据驻留在此处,操作系统以这种方式跨进程共享。
- 系统为每个进程的每个区域(P0 和 P1)提供了一个页表,存放在内核虚拟内存中。
- 一个基址寄存器保存该段的页表的地址,界限寄存器保存其大小(即页表项的数量)。
- 由于页表在系统虚拟内存中,于是当硬件需要查询进程内存地址时需要进行两次转换,一次访问内核页表,第二次才是真正的页表项,好在 TLB 让这些工作不那么费劲。
- 后半段为进程空间(S)
- 在进程空间的前半部分(称为 P0)中,有用户程序和一个向下增长的堆。
- 在进程空间的后半部分(P1),有向上增长的栈。
一个真实的地址空间
- 对于每个进程来说,它能看见的内存地址由两部分组成:
- 前半段为用户空间
- 后半段为内核空间
代码段永远不会从第 0 页开始。相反,该页被标记为不可访问,以便为检测空指针(null-pointer)访问提供一些支持。因此,设计地址空间时需要考虑的一个问题是对调试的支持,这正是无法访问的零页所提供的。
内核虚拟地址空间(即其数据结构和代码)是每个用户地址空间的一部分。在上下文切换时,操作系统改变 P0 和 P1 寄存器以指向即将运行的进程的适当页表。但是,它不会更改 S 基址和界限寄存器,并因此将“相同的”内核结构映射到每个用户的地址空间。
内核映射到每个地址空间,这有一些原因。这种结构使得内核的运转更轻松。例如,如果操作系统收到用户程序(例如,在 write()系统调用中)递交的指针,很容易将数据从该指针处复制到它自己的结构。操作系统自然是写好和编译好的,无须担心它访问的数据来自哪里。相反,如果内核完全位于物理内存中,那么将页表的交换页切换到磁盘是非常困难的。如果内核被赋予了自己的地址空间,那么在用户应用程序和内核之间移动数据将再 次变得复杂和痛苦。通过这种构造(现在广泛使用),内核几乎就像应用程序库一样,尽管是受保护的。
显然,操作系统不希望用户应用程序读取或写入操作系统数据或代码。因此,硬件必须支持页面的不同保护级别才能启用该功能。 VAX 通过在页表中的保护位中指定 CPU 访问特定页面所需的特权级别来实现此目的。因此,系统数据和代码被设置为比用户数据和代码更高的保护级别。试图从用户代码访问这些信息,将会在操作系统中产生一个陷阱,并且可能会终止违规进程。
页替换
VAX 中的页表项(PTE)包含以下位:
- 一个有效位
- 一个保护字段(4 位)
- 一个修改(或脏位)位
- 为 OS 使用保留的字段(5 位)
- 最后是一个物理帧号码(PFN)将页面的位置存储在物理内存中
敏锐的读者可能会注意到:没有引用位(no reference bit),VMS 替换算法必须在没有硬件支持的情况下,确定哪些页是活跃的。
还有一个问题是“自私贪婪的内存”(memory hog)—— 一些程序占用大量内存,使其他程序难以运行。到目前为止,我们所看到的大部分策略都容易受到这种内存的影响。 例如,LRU 是一种全局策略,不会在进程之间公平分享内存。
分段的 FIFO
想法很简单:每个进程都有一个可以保存在内存中的最大页数,称为驻留集大小(Resident Set Size,RSS)。每个页都保存在 FIFO 列表中。当一个进程超过其 RSS 时,“先入”的页被驱逐。FIFO 显然不需要硬件的任何支持,因此很容易实现。
正如我们前面看到的,纯粹的 FIFO 并不是特别好。为了提高 FIFO 的性能,VMS 引入了两个二次机会列表(second-chance list),页在从内存中被踢出之前被放在其中。
具体来说,是全局的干净页空闲列表和脏页列表。当进程 P 超过其 RSS 时,将从其每个进程的 FIFO 中移除一个页。如果干净(未修改),则将其放在干净页列表的末尾。如果脏(已修改),则将其放在脏页列表的末尾。如果另一个进程 Q 需要一个空闲页,它会从全局干净列表中取出第一个空闲页。但是, 如果原来的进程 P 在回收之前在该页上出现页错误,则 P 会从空闲(或脏)列表中回收,从而避免昂贵的磁盘访问。
这些全局二次机会列表越大,分段的 FIFO 算法越接近 LRU。
页聚集
对于小页面,交换过程中的硬盘随机 I/O 效率非常低,因为硬盘在连续 I/O 效果更好。为了让交换 I/O 更有效,VMS 增加了一些优化,但最重要的是聚集(clustering)。通过聚集,VMS 将大批量的页从全局脏列表中分组到一起,并将它们一举写入磁盘(从而使它们变干净)。
聚集用于大多数现代系统,因为可以在交换空间的任意位置放置页,所以操作系统对页分组,执行更少和更大的写入,从而提高性能。
按需置零
利用按需置零,当页添加到你的地址空间时,操作系统的工作很少(在页表中标记一下而不是直接置零)。
- 它会在页表中放入一个标记页不可访问的条目。
- 如果进程读取或写入页,则会向操作系统发送陷阱。
- 在处理陷阱时,操作系统注意到(通常通过页表项中“保留的操作系统字段”部分标记的一些位),这实际上是一个按需置零页。
- 此时,操作系统会完成寻找物理页的必要工作,将它置零,并映射到进程的地址空间。
- 如果该进程从不访问该页,则所有这些工作都可以避免,从而体现按需置零的好处。
写时复制
如果操作系统需要将一个页面从一个地址空间复制到另一个地址空间,不是实际复制它,而是将其映射到目标地址空间(共享内存),并在两个地址空间中将其标记为只读。
- 如果两个地址空间都只读取页面,则不会采取进一步的操作,因此操作系统已经实现了快速复制而不实际移动任何数据。
- 如果其中一个地址空间确实尝试写入页面,就会陷入操作系统。
- 操作系统会注意到该页面是一个 COW 页面,因此(惰性地)分配一个新页,填充数据,并将这个新页映射到错误处理的地址空间。
- 该进程然后继续,现在有了该页的私人副本。
任何类型的共享库都可以通过写时复制,映射到许多进程的地址空间中,从而节省宝贵的内存空间。在 UNIX 系统中,由于 fork()和 exec()的语义, COW 更加关键。你可能还记得,fork()会创建调用者地址空间的精确副本。对于大的地址空间,这样的复制过程很慢,并且是数据密集的。更糟糕的是,大部分地址空间会被随后的 exec()调用立即覆盖,它用即将执行的程序覆盖调用进程的地址空间。通过改为执行写时复 制的 fork(),操作系统避免了大量不必要的复制,从而保留了正确的语义,同时提高了性能。
按需置零和写时复制都是惰性(lazy)优化:惰性可以使得工作推迟,但出于多种原因,这在操作系统中是有益的。首先,推迟工作可能会减少 当前操作的延迟,从而提高响应能力。